CPU Cache介绍
随着CPU频率的不断提升,内存的访问速度却并没有什么突破。所以,为了弥补内存访问速度慢的硬伤,便出现了CPU缓存。它的工作原理如下:
- 当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;
- 如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
为了充分发挥CPU的计算性能和吞吐量,现代CPU引入了一级缓存、二级缓存和三级缓存,结构如下图所示:
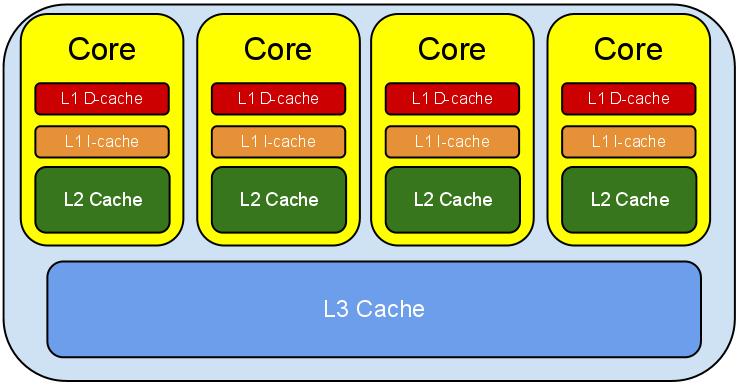
图中所示的是三级缓存的架构,可以看到,级别越小的缓存,越接近CPU,但访问速度也会越慢。
- L1 Cache分为D-Cache和I-Cache,D-Cache用来存储数据,I-Cache用来存放指令,一般L1 Cache的大小是32k;
- L2 Cache 更大一些,例如256K, 速度要慢一些, 一般情况下每个核上都有一个独立的L2 Cache;
- L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
当CPU计算时,首先去L1去寻找需要的数据,如果没有则去L2寻找,接着从L3中寻找,如果都没有,则从内存中读取数据。所以,如果某些数据需要经常被访问,那么这些数据存放在L1中的效率会最高。
下面的列表表示了CPU到各缓存和内存之间的大概速度:
| 从CPU到 | 大约需要的CPU周期 | 大约需要的时间(单位ns) |
|---|---|---|
| 寄存器 | 1 cycle | |
| L1 Cache | ~3-4 cycles | ~0.5-1 ns |
| L2 Cache | ~10-20 cycles | ~3-7 ns |
| L3 Cache | ~40-45 cycles | ~15 ns |
| 跨槽传输 | ~20 ns | |
| 内存 | ~120-240 cycles | ~60-120ns |
在Linux中可以通过如下命令查看CPU Cache:
|
|
这里的index0和index1对应着L1 D-Cache和L1 I-Cache。
缓存行Cache Line
缓存是由缓存行组成的。一般一行缓存行有64字节。CPU在操作缓存时是以缓存行为单位的,可以通过如下命令查看缓存行的大小:
|
|
由于CPU存取缓存都是按行为最小单位操作的。对于long类型来说,一个long类型的数据有64位,也就是8个字节,所以对于数组来说,由于数组中元素的地址是连续的,所以在加载数组中第一个元素的时候会把后面的元素也加载到缓存行中。
如果一个long类型的数组长度是8,那么也就是64个字节了,CPU这时操作该数组,会把数组中所有的元素都放入缓存行吗?答案是否定的,原因就是在Java中,对象在内存中的结构包含对象头,可以参考我的另一篇文章Java对象内存布局来了解。
测试Cache Miss
下面的代码引用自http://coderplay.iteye.com/blog/1485760:
|
|
这里测试的环境是macOS 10.12.4,JDK 1.8,Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)。
这里定义了一个二维数组,第一维长度是1024*1024,第二维长度是62,这里遍历二维数组。由于二维数组中每一个数组对象的长度是62,那么根据上篇文章Java对象内存布局的介绍,可以知道,long类型的数组对象头的大小是16字节(这里默认开启了指针压缩),每个long类型的数据大小是8字节,那么一个long类型的数组大小为16+8*62=512字节。先看一下第一种慢的方式运行的时间:
|
|
运行时间是11秒多,再来看下快的方式:
|
|
运行时间是888毫秒,还不到1秒,为什么相差这么多?
首先来分析一下第一种情况,因为二维数组中的每一个数组对象占用的内存大小是512字节,而缓存行的大小是64字节,那么使用第一种遍历方式,假设当前遍历的数据是longs[i][j],那么下一个遍历的数据是longs[i+1][j],也就是说遍历的不是同一个数组对象,那么这两次遍历的数据肯定不在同一个缓存行内,也就是产生了Cache Miss;
在第二种情况中,假设当前遍历的数据是longs[i][j],那么下一个遍历的数据是longs[i][j+1],遍历的是同一个数组对象,所以当前的数据和下一个要遍历的数据可能都是在同一个缓存行中,这样发生Cache Miss的情况就大大减少了。
总结
一般来说,Cache Miss有三种情况:
- 第一次访问数据时cache中不存在这条数据;
- cache冲突;
- cache已满。
这里的第二种情况也比较常见,同时会产生一个问题,就是伪共享,有时间会单独写一篇文章来介绍一下Java中对伪共享的处理方式。